AI, Deep Learning, Machine Learning are the top trending topics in the IT industry and every company will one day have to deal with these new topics. But where to start and why should you be very careful when you start a Deep Learning or Machine Learning project from scratch?
I know…. perhaps your boss said you must put some AI-stuff in your application’s code so that the customer is happy to have a product containing “some kind of AI”. I’ve seen this situation several times especially in tiny companies which programmed for years domain specific applications (e.g. industry, accountancy) and due to the hype of Deep Learning are trying their best to catch the AI train as fast as possible and add sort of AI. At the end this might lead to problems and mistakes. I’ve collected some advices and also mistakes you can do when you start a Deep Learning or Machine Learning project from scratch. Have fun!
Understand your data!

Sometimes everything needs to go fast, and your boss comes with a wonderful 10 GB Excel File from a customer and tells you that the customer needs a TensorFlow model for next week. Of course, *irony-mode-on* “everything is simple you only need to check the table and the headers are self-explanatory- a simple regression with a classification will do the thing" irony-mode-off
- Invest enough time to understand and analyze the data yourself. If you are unsure about the data, ask for a documentation. Don’t rely on data which you don’t know the source and its producer (e.g., a machine sensor, automatic export out of an SAP system or pulled from a REST-Interface or Webservice). Some datasets might be not complete (think of sensors with failures).
- Don’t overlook the data cleaning and conversion tasks e.g., from Excel to CSV / JSON: take your time and please check that the conversion worked (are the comas correct, the units converted?)
- Have you checked that all data are meaningful and NULL, empty values are filtered out? Perhaps you will also find outliners.
- Understand the semantics of the data and if it’s unclear ask the client. I’ve seen so many CSV-File with headers like value_1, value_2 etc.… without any comments and units.
- In some fields (e.g. medicine, banking) it’s necessary to anonymize your data and remove critical information. Sometimes a data protection officer is needed to clarify the content of the data and to check that the GDPR regulations are respected. Don’t overlook this step: it’s a crucial one even if it is not a technical one.
- Do not rush directly to the model design: a well-structured data basis is like building a house on solid foundations.
Deep Learning != GPU and graphic cards

One misleading information clients have is that you need to buy a lot of GPUs to train a model. This might be the case, but for prototypes or first trials you should evaluate whether it makes sense to buy GPUs or if it’s not better to rely on cloud-based services that offers an access to more performant hardware for less money. Here I would advise you the following:
- Cost analysis: Training configuration vs. Hardware acquisition vs. Project’s budget. If you have the feeling that you need to spend a lot of money into hardware acquisition only to train your model you must think about cloud-based solutions (Google, Microsoft, IBM, AWS)
- For some specific tasks like NLP, translation, REST-based services (like Alyen, Natif.ai etc…) might better suit your needs: you don’t have to reinvent the wheel if for a few cents you’ll get the same result.
- Don’t forget: Hardware can become obsolete very quickly
- And… sometimes configurating this hardware requires some skills (driver installation like CUDA, sometimes compiling drivers from sources etc…) and a good knowledge on specific APIs
- If you are going to use TensorFlow, why not using TPUs (Tensor Processing Units) which are available on Google Colab and in form of dedicated Hardware (Google Coral) to start your project? This will give you a good starting point to decide whether you need to really invest in expensive graphic cards to train your models
Beware the “GitHub temptation” to build up your own DL-Project

This is almost a beginner’s pitfall: your boss wants AI to solve a problem, you google it and then you will certainly find a somehow suitable GitHub Project. You make a clone et voilà: your project is done…Seems like a dream, but it’s the beginning of your dev nightmare!
- Legal stuff and usage condition is the first nightmare: Please check the licenses of the models (e.g. MIT License, Creative Commons Attribution 3.0 License, Apache 2.0 license, etc…) and on what data they were trained. Sometimes the model is said “open source” but the training data might be copyrighted.
Even on free model zoos like TensorFlow Hub (https://tfhub.dev/), you have to be careful
- And yes… some models or code parts are not allowed to be used in commercial applications.
- Put time to really understand what the model really does. I mean its architecture, structure and to check it’s derived from another one (e.g.VGG16)
- Don’t forget you want a happy customer, so you must customize your model on his needs. It’s questionable that you will find a 1:1 suitable on GitHub
- Be kind enough to cite or link the authors of models if you used them. It’s a good practice in the community to do so and kind of a big up for them: students at universities and research institutes have put a lot of their energy and time to develop and train models. One good source is PapersWithCode (https://paperswithcode.com/)
The framework dilemma

TensorFlow, PyTorch, scikit-learn, C++, Python, R, JavaScript? This reminds me of the debate “Linux vs Windows vs MacOS”: there is definitely no answer which framework is the best. The answer is: it depends on what you are trying to achieve and what the customer wants… TensorFlow and Keras are the most used in the community, but it doesn’t mean that PyTorch or Scikit are less good.
If you are totally unsure where to start, I encourage you for the data exploration part to use scikit-learn. With simple to understand functions and powerful matrix and arrays manipulation operations you can easily gain a good insight of your dataset.
Then you can go for Keras (which is included in TensorFlow) and simply build up your model. The syntax is very easy to understand, and, in a few lines, you will be able to training something complex.
If you only want to do some minimal machine learning stuff, let’s say “on the go” and in your web browser (with no big installation), here a framework like TensorFlow.js will be
But what about programming language? Beside R, Python is almost THE language to know when you start with a deep/machine learning project. If you have a client who doesn’t work with Python but you have implemented everything in Python… then I can give you the advice of wrapping your code as a REST-Service with Flask. Of course, there are more complex possibilities like TFX and TensorFlow Serving for serving your models.
If your model should be distributed, run in a Docker container or on GPUs I highly recommend to use TensorFlow (with Keras) as here you have a strong community and the support of Google engineers.
Never promise a 99% accuracy

.. or fixate on something like metrics, training speed, because you will never reach it, even if you are a deep learning guru. You can be happy if the model you’ve built up from scratch reaches a good 95%. The last 1 to 5% of a task are the hardest to achieve
- The same with training duration: it’s hard to evaluate how long a training will last. It’ll depend on the data you inject and the complexity of your model. Of course if you see after a half-an-hour that your model is not learning anymore, you will deduce that either the task is not so complex
- Never tell a customer that your model will recognize everything with an accuracy of xxx %: always have a proof in form of a benchmark dataset or a test set.
- If you are working with new data, never commit to metrics (RMSE, R2 Accuracy) before you have fully analyzed and understood the data you are working on!
- Always try to change your test data to counter check if the accuracy is still as high as expected
Beware of Overfitting
You will certainly find within a few hours a suitable model for your task. The client will be satisfied, but a few days later he will call you and say that “it doesn’t work well anymore”.
Over and Underfitting are the nightmare of any deep learning specialist
- The quality of a learned neural network model can be determined by its generalization. After training, the network must be able to process never-before-seen patterns as correctly as possible.
- However, if the learned model has high precision on training data but performs poorly on never-before-seen data, it is said to be overfitting or underfitting
- Use early Callbacks like EarlyStopping (https://keras.io/api/callbacks/early_stopping/) to stop training when a given metric has stopped to improve
Don’t believe everything what you see on YouTube

Oh yes, we all know those “script kiddies” that want to teach you how to detect a cat within a video in only 5 minutes with their “own self trained TensorFlow model”…Seriously? I’ve watched several videos on “Object detection” but left the boat because they all have hidden the fact, they were using YOLO and tuned some parameters in the background () without giving a reasonable explanation (like learning_rate parameter?). Don’t get me wrong: YouTube is a very good educational source, but you must check following points:
- Your customer expects a customized solution from you and not cut-n-pasted stuff from a student’s YouTube channel.
- Training times are sometimes simply skipped by the YouTubers!
- Beware of aspects like data source and copyright problems.
No data == No model??

It’s the modern version of the chicken and egg problem that comes back in almost every pre-project discussion: “We have no data, but we want to train a model…”. If in 80 percent of the cases this is a real problem, sometimes you must be creative to generate your own data.
The basic idea: synthetic data is used to train models on data, that do not exist in a dataset, for example. In this way, certain situations and contexts can be simulated without having been recorded in reality. Think of autonomous driving where synthetic data is being increasingly used. Nobody wants to really generate an accident to have data of an accident. You get me? So huge picture datasets of potentially dangerous situations are generated by a computer (e.g. a child running across the road, a car braking violently in heavy rain).
And sometimes you have so few data, that you actually need more to correctly train a model: this is where data augmentation plays a role.DL-Frameworks like Keras offers so called data generators which generates new (unseen) data with variations. One of them, the ImageDataGenerator performs real-time data augmentation during the training. With the ImageDataGenerator only the generated images of the current batch are used as input and for instance the brightness, the scale, the rotation of the initial picture is modified to generate new data. The CPU performs the data augmentation and meanwhile the GPU is used for training. Both tasks (training and data augmentation) can thus be executed in parallel.
- Synthetic data can help further
- Why not building a sensor simulator that outputs values (and sometimes fuzzy ones) to generate a dataset you can train on?
- Data generation should be carefully documented and prepared!
- Deliberately integrate false positives or non-matching data into your data set!
- Derived from real data: Adding effects like blurring, stitching....
- Test, verify, improve, generate
If you really have no other option, invest some time to browse through following wonderful dataset sources
Kdnuggets also has a huge list of freely usable datasets: https://www.kdnuggets.com/datasets/index.html
- Be creative! Think of DeepL which built up their whole translation models on the web-based service Linguee using open text sources that have already been translated by humans into several languages the official Web pages or texts of the European Parliament
- If you are starting from scratch and don’t have any time or the motivation to annotate/label huge amount of data think of services like Amazon Mechanical Turk or like Fiverr
Beware of the biggest danger: Biases

Nobody wants her selfie to be classified as “monkey” or that a chat bot after a few minutes of conversation starts to yell at you because he has misclassified your sentences. As ML only relies on data (without context), the latter should be always statistically controlled.
- Check with statistics if classes are balanced and correctly represented in the dataset
- Always counter check with new data to check if some artefacts and biases remains
- The data collection should always be done seriously and not à la “let us quickly grab some random data from Google Images”
- If you have the feeling that the model you have built is prone to biases, you have to inform your client. It’s better to know it in an early development stage so more balanced data can be generated/found and integrated into the training pipeline.
- Know what you are modelling and do it in an ethical and transparent way. Always ask yourself: “Is my model going to discriminate someone?”
Keep It Easy and repeat again:… Keep it Easy

Not all problems must be mandatory solved with ML/DL because it sounds “cool”. Some easy tasks might be solvable with simple means Even I’m a big fan of TensorFlow and Keras, some task can be also solved with a one-liner by using sci-kit learn
- Many data ≠ Good data
- Patience and documentation
- Always explain model challenges, metrics, and results to your clients
If you are completely lost why not trying Lobe.ai (by Microsoft) or Teachable Machine (by Google)? to quickly build your classifiers?
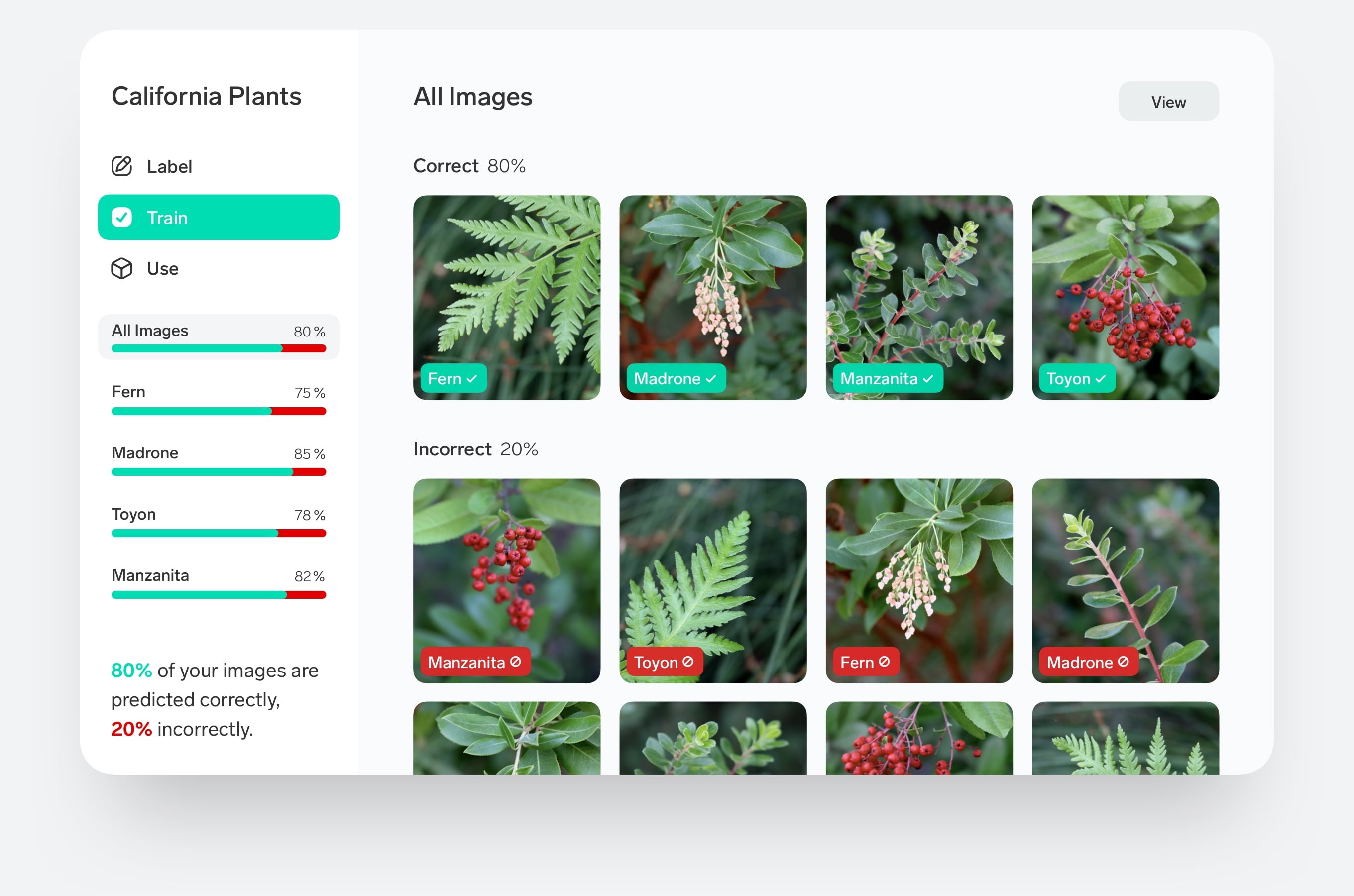
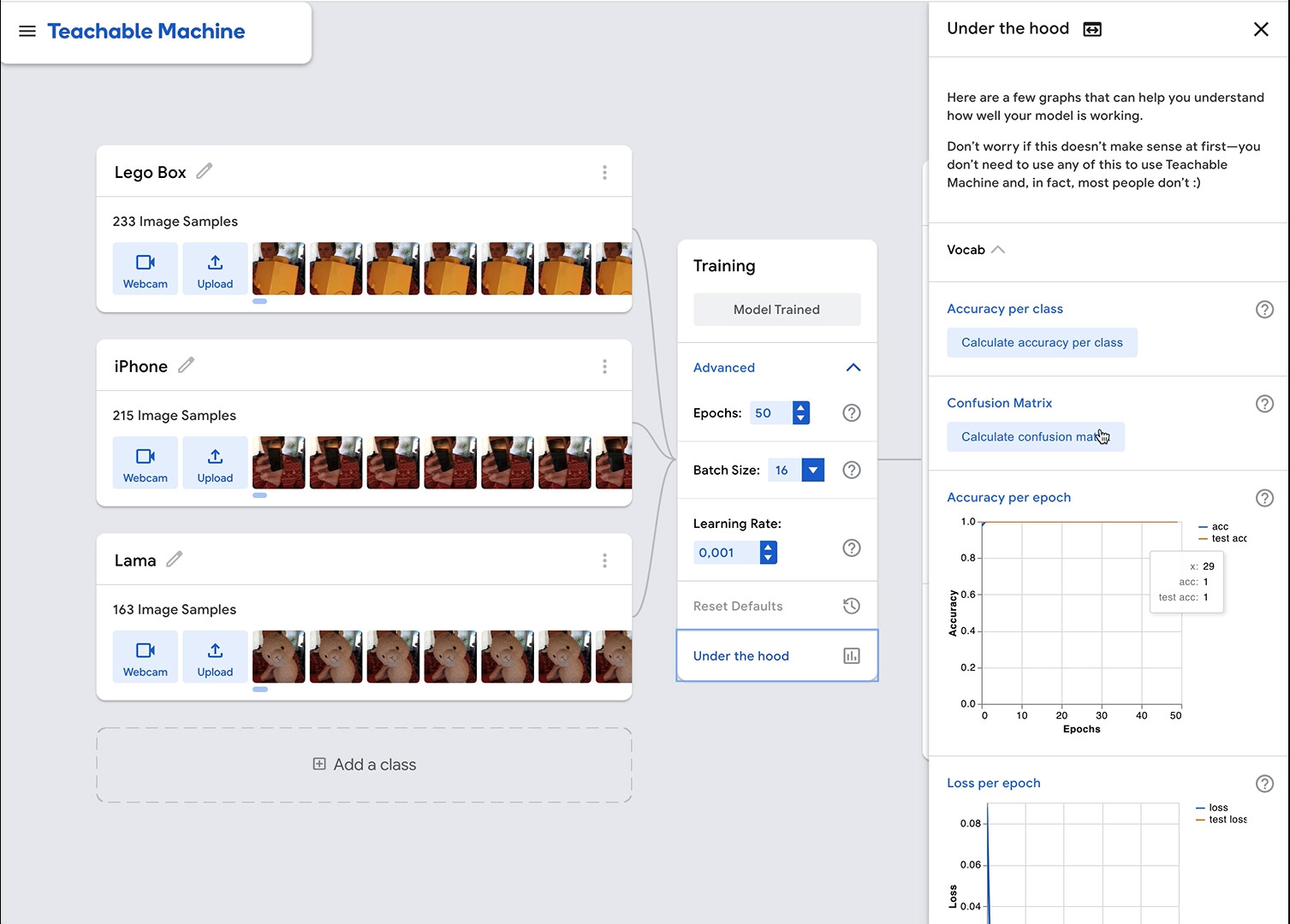
These tools are so easy to use and will help you to build up your models based on images, videos or text within a few minutes and without big knowledge about neural networks, layers etc..
If you are looking for a more artistic usage of Deep Learning (Style transfer, Focus, removal of objects effects) I really recommend you use RunwayML and its editor.
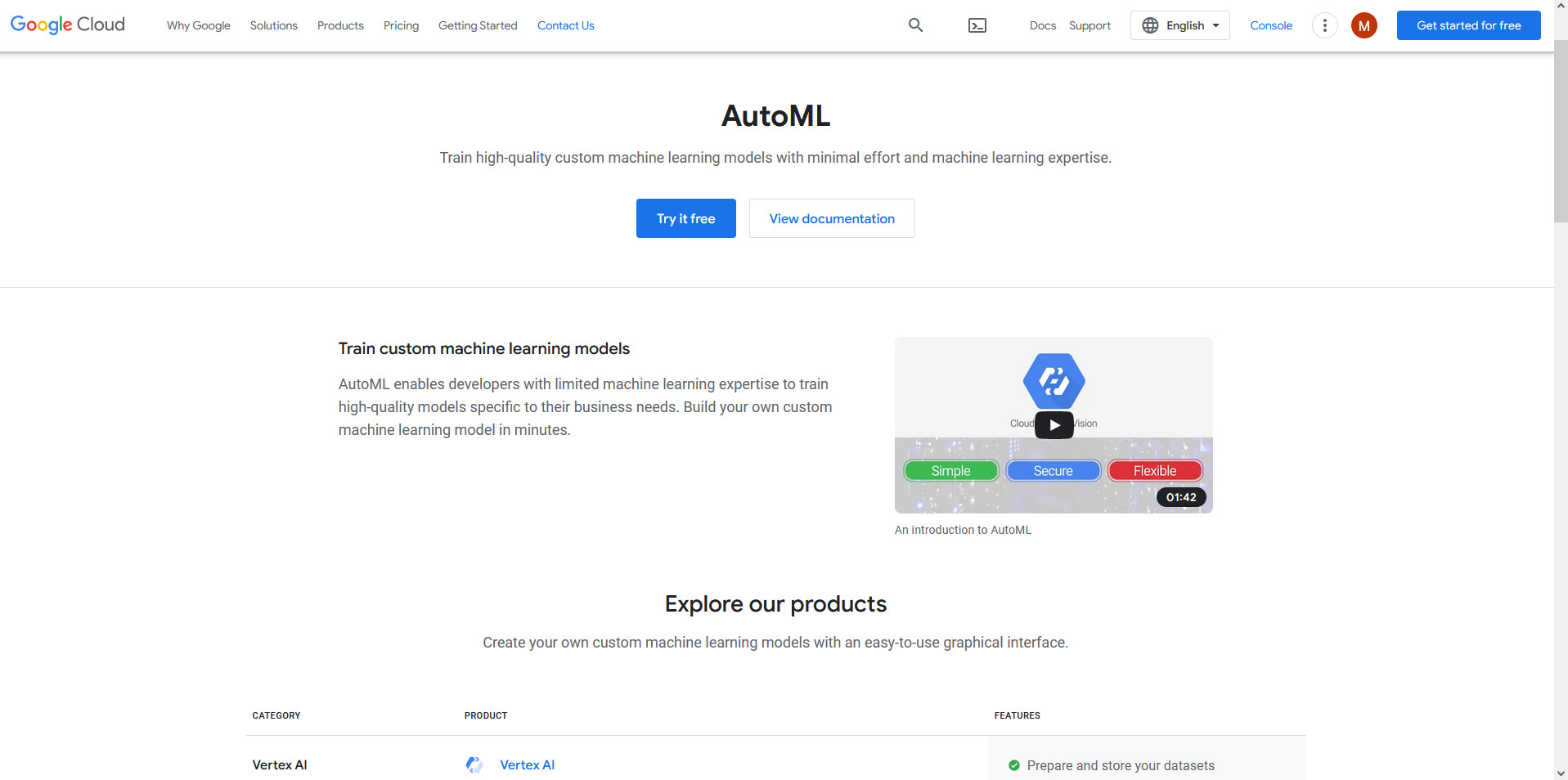
Bonus: For the lazy Deep Learning devs among us: use AutoML!

What if the appropriate model was automatically suggested and created based on the datasets? This is currently the most interesting hype in the ML-Word: You only have to specify which input data you have (e.g. images) and which task you’d like to perform on this data (e.g. a classification).In the background, the system will automatically create (better said: search) the most suitable models for you (it’s called: Neural Architecture Search).
It sounds magical and in this field, which is relatively new, there are competing different approaches: on the one hand, commercial solutions such as Google Cloud AutoML and on the other hand, open source projects like AutoKeras or H2O.
So, you lazy devs next time: no more excuses for not delivering a model 😉
Image credits: balasoiu, macrovector, rosapuchalt - freepik.com
Do you need personalized help and support for starting your next Deep Learning project? Then don't hesitate to contact me! I'm offering exclusive consulting services and webinars around Deep Learning (see Shop section).